| Author: | Martin Blais <blais@furius.ca> |
|---|---|
| Date: | 2006-03-30 |
Abstract
A description of the Python scripts and infrastructure that is provided around xxdiff, to facilitate implementing processes requiring display and selection of differences.
Contents
xxdiff is a computer program that allows a user (usually a software developer of some sort) to easily visualize the differences between files. The manner and goal for which this process is applied over multiple files is highly dependent on the application, and most of the time is driven by custom user scripts.
For example, a configuration management engineer in a company might provide some kind of merge policing environment, that allows software developers to review changes in files for the purpose of accepting or rejecting a submitted changeset to a codebase. Another example is that of a developer wishing to review the changes he made to a checkout of files from a source-code management system such as CVS, Subversion, ClearCase, Perforce, etc.
xxdiff has been developed in a corporate environment with hundreds of users. Over time, it has been progressively augmented with features to allow it to better interact with caller scripts, and many of Python scripts were provided as open source on the internet, to perform various common tasks. It was only natural that at some point in time common code between these programs should be shared in a library, and a Python package provided to ease the task of writing other, new, custom scripts.
This document describes this package, and the scripts that are provided along with xxdiff, implemented using the same code.
The prototypical task of carrying out a merge is that of visualizing and accepting or rejecting all or some changes to a file, changes from a source file (e.g. in the case of an update, these are changes forced by other developers) to a target file (in that case, files living in a developer's own checkout). There are three possibilities:
xxdiff already provides the ability to interactively select diff hunks from either files to produce a merged output file.
Therefore, in order to answer the needs above in the context of a script querying the user for actions to be carried out, a special mode was added to xxdiff, that forces the user to answer with either “accept”, “reject” or “merge” [1]. xxdiff takes special precautions to ensure that the file you decide to output is complete, for example, if you answer with merge, it insures that you have made a decision about all the diff hunks.
| [1] | This mode is invoked with the --decision switch, and the corresponding keys are A, R and M. |
A very commonly occuring case is that of having to loop over multiple files for changes, either from an update from a source code repository, or applying a set of modifications to a file via a program--such as sed--and reviewing and accepting those changes. The high-level algorithm looks like this:
Recurse in directories, selecting files.
For each file selected
Apply automated changes to the file
OR
Fetch the different versions of the file
Launch xxdiff in decision mode to find out what action to perform
xxdiff runs, while the parent script waits
Conditionally replace the target file with the result of the merge (or
simply, with the newer file, in case of ACCEPT).
There are many functionalities involved:
The provided scripts allow you to carry out some of these tasks in different combinations.
File backups are automatically created. There are a few options about where to put the backup files:
Along with the original files, but with an added extension, e.g.:
source.cpp source.cpp.bak.1 source.cpp.bak.2
In a separate directory, recreating the directory hierarchy there (just for the backed up files).
All backup options:
File backup options:
These options affect automatic backup of overwritten files.
-b CHOICE, --backup-type=CHOICE
Selects the backup type from: along, other, none
--backup-dir=BACKUP_DIR
Specify backup directory for type 'other'
Note that if you're using the same directory for backups over multiple runs, if some files are the same, the backed up files get overwritten (a warning is displayed).
Some SCM systems require the user to checkout files to make them writable, like ClearCase (under certain configurations). There are options to do that.
There is a --no-confirm option that runs the transformation, accepting the changes on all the files, producing a nice log of all the changes applied, without querying the user with a graphical diff at all. This is useful when you've started confirming changes and after checking many files you've become confident that your transformation code will not fail. If you have a large codebase to process, you may prefer to just apply unconditionally and them visualize the changes in the textual side-by-side diff log.
We can easily implement the (c) part without embedding it in a loop.
This program is akin to the UNIX command cp, but its actions are conditional to your feedback within xxdiff. If you accept, the target file is overwritten with the contents of the source file. If you reject, nothing happens to the target file. If you merge, the target file is overwritten with the contents of the merged results.
This allows you to write the produce the modified file yourself and to write the loop in, for example, Bourne shell:
# Remove all empty lines in files
find . -name '*.txt' | while read i ; do
cat $i | tr -s \\n | xx-cond-replace - $i ;
done
Important
Note that for this program the backups are not enabled by default. Since every invocation is separate, if the backups were on by default a unique backup directory would be created for each invocation. You can imagine that this would create a lot of goo in the temporary directory.
If you want to backup all the files from a loop run to a single backup directory root, make sure to use the --backup-dir option.
Many of the find-loops that occur in practice are very simple, e.g. replace a string in all the files ending with .h and .cpp. For this purpose, we have implemented a few scripts that perform the loop for you. This is the functionality mentioned as (a) in the introduction.
These scripts all work from the same loop: a recursive walk of all the files in a set of root directories, by default the current directory. The selection process embodies common patterns for selecting files.
You can restrict and ignore files by filename, for example, to select all the .html and .htm files, you could use:
xx-rename -I \.svn --select='.*.htm$' --select='.*.html$' ...
Note
The ignore patterns works on directories, but the select patterns do not.
There are switches that allow you to grep the files for some patterns in order to determine if they should be processed or not, e.g.:
xx-rename --select-grep='^#include' FROM TO
You can also instruct the scripts to work on a fixed set of filenames, which you provide via a file:
xx-rename --select-from-file=/tmp/procfiles FROM TO
Where /tmp/procfiles would have been generated by your beforehand, in any way you like.
Here is the full set of options (as of [2006-03-31]):
File selection options:
These options affect which files are selected for grepping in the
first place.
-s REGEXP, --select=REGEXP
Adds a regular expression for filenames to process.
-I REGEXP, --ignore=REGEXP
Adds a regular expression for filenames to ignore.
--cpp, --select-cpp
Adds a regular expression for selecting C++ files to
match against.
--py, --select-py Adds a regular expression for selecting Python files
to match against.
--select-grep=REGEXP
Further restrict the files to those which match the
given regular expression.
--ignore-grep=REGEXP
Do not select files to those which match the given
regular expression.
-f FILE, --select-from-file=FILE
Do not recurse through directories to find files but
instead read the list of filenames from the given
file.
-r ROOTS, --root=ROOTS
Specify a root to perform the search from (default is
CWD). You can use this option many timesfor multiple
roots.
To test which files are going to be selected before running your modification command, you can use the --select-debug switch (or -@) to view the list, e.g.:
xx-rename --cpp 'Application', 'LargeApplication' -@
Would give output like this, without running any graphical diff at all:
/home/blais/p/xxdiff/src/builderFiles3.h /home/blais/p/xxdiff/src/diffutils.h /home/blais/p/xxdiff/src/scrollView.h /home/blais/p/xxdiff/src/diffs.h /home/blais/p/xxdiff/src/accelUtil.cpp /home/blais/p/xxdiff/src/app.inline.h ...
This script invokes the selection loop (a), runs a command that you specify and invokes xxdiff on each result (c). It basically directs the process, and runs should UNIX filter command in a shell for you. You command must be a filter, that is, it takes each file as stdin and outputs the modified file as stdout.
For example, repeating the previous example:
xx-filter 'tr -s \\n'
The output will be a log of all the decisions that were made and all the changes that were applied, as a side-by-side log.
By far, the most common use case for this kind of process is that of renaming a string or text matched by a regular expression by another string. This works similarly to the sed s/FROM/TO/g program expression.
Here is an example invocation:
xx-rename FrobnicatorBaseClass FrobnicatorBase
Note that you can also specify more than one from/to rename pair and all the renamings are applied in the same run, in the same order that they appear on the command-line:
xx-rename from1 to1 from2 to2 from3 to3
This script is a relic of the past, the actual ancestor to all of this. You see, this used to be a Bourne shell script, before it became something called cc_multi--its first Python incarnation. We then used to perform a grep in a subprocess, to find out if the file should be processed (if it matched the pattern), followed by a sed subprocess to perform the actual change.
Here is an example invocation:
xx-find-grep-sed 'class Frobni.*' 's/Frobnica/Brofnica/g'
Today we have a much more generic version of the same idea:
xx-filter --select-grep='class Frobni.*' "sed -e 's/Frobnica/Brofnica/g'"
There xx-find-grep-sed is a bit obsolete. I mean, it still works fine, and I provide it to support those who already have it in their process, but really, it should go.
In the Python cookbook, this recipe proposes to compile and run a Python expression on lines, similar to sed, but just using Python code. With the new scripting infrastructure, it was trivial to build another transformation program that uses that method. Here is an example:
xx-pyline -m os "os.stat(line).st_size > 1024 and line"
With the provided Python package, it is quite easy to create a new program to process a file in your own very customly way and to use the visualization and confirmation loop described above. You need to do the following:
Implement a transformer class that will perform the file transformation:
class CustomTransformer(xxdiff.xformloop.Transformer):
def transform( self, fn, outf ):
text = open(fn, 'r').read()
newtext = ... # transform text somehow
outf.write(newtext)
return True
You can return False to skip the file in that method. You can also initialize your transformer with the parameters of your transformation, if needed.
Add your own options and parse the arguments with the provided loop's method:
import optparse
parser = optparse.OptionParser()
parser.add_option('-M', '--my-option', action='store_true',
help="My custom special option for my transformer.")
opts, args, selector = xxdiff.xformloop.parse_args(parser)
Do your own arguments validation, if your script takes arguments.
Create an instance of your transformer and use our main loop to invoke it over the selected files:
# Create an appropriate transformer.
xformer = CustomTransformer(opts, <custom-arguments...>)
xxdiff.xformloop.transform_replace_loop(
opts, selector, xformer, sys.stdout)
Some simplistic details are omitted, but that is the gist of it. You can use the scripts provided with the package as examples, they all follow that pattern.
One day, a silly man asked me the following question via email:
“Why is it that when I call xxdiff dir1/*.c dir2/*.c it doesn't work?”
The answer is simple: the globbing patterns get expanded by the shell and not by xxdiff itself. xxdiff only gets a large list of files, and clearly, there isn't much it can do... almost.
I thought, “hey, maybe I can do something for this person” and I wrote xx-match. It just builds a map of basenames and runs diffs on sets of matching basenames. The result: it mostly works like the gentleman wanted it.
So there.
I provide the script for educational value more than anything else (or for those who really like that syntax).
Note that the matching algorithm can be implemented separately, and therefore is a more generic version of this available in my pubcode directory: match-files, e.g.:
match-files -x '--single' dir1/*.c dir2/*.c | xargs -n2 xxdiff
I wanted to be able to preview the changes that I had made in a CVS checkout. This script does it. It pulls the original versions from the server by using cvs diff, which is very efficient as it provides a single file with all the diffs (a patch). The patch is then applied to temporary files to visualize the changes.
Unfortunately, I never wrote much more than this for CVS, but with the new packaged architecture of xxdiff Python code it should be easy to create new scripts for it if you need to.
Back in the days where xxdiff did not have any scripts, I implemented unmerging of CVS conflict markers directly in xxdiff itself (should I have to do this today I would definitely implement that in a script instead). Just can just invoke xxdiff with the --unmerge or --unmerge3 options to do that.
Since 2005, I have switched my repository of files to Subversion and I will therefore begin producing more support for this SCM.
If you use any of the looping scripts described before in a Subversion checkout, you can avoid changing the administrative files stored in the .svn directories by using the following ignore option:
xx-rename -I .svn ...
Note that by default Subversion and CVS directories are ignored (you can disable that with an option).
Subversion has a diff subcommand:;
svn diff
It also has the ability to let you specify which diff program you want to use to actually display the diffs. This program has to behave like GNU diff, i.e. the options it accepts, the return value, etc.
xx-diff-proxy is a script whose interface is compatible with being invoked from Subversion, but that displays the diffs graphically rather than textually, using xxdiff. You can configure this per-user by adding the following lines to your ~/.subversion/config file:
[helpers] diff-cmd = xx-diff-proxy diff3-cmd = xx-diff-proxy
Important
Note: there have been reports of bugs in certain cases. I still need to investigate in which cases it breaks down because I have not had problems with it yet, I have not experienced bugs.
In my opinion, Subversion provides a diff loop that is rather weak. I want more options in the ways that I can review my changes. xx-svn-diff runs svn status and then loops over the files using xxdiff.
A problem with the approach described in the xx-diff-proxy section above is that I want to also have normal svn diff behaviour (i.e. textual output) and I don't want to hack my config file everytime I want to do this.
It is a good script to use instead of svn commit:
Subversion provides a fancier version of conflict resolution: all three files-- yours, the other and the ancestor--are provided in your checkout to help you figure out what happened. This is a perfect situation for xxdiff: I simply can invoke it with the 3 files, ignoring the automatic merging that took place within Subversion, and providing the user with the interactive merge capabilities within xxdiff to resolve the conflicts, if possible.
Then the user's changes can be applied automatically over the merged file and we can call svn resolve as well to clear it (optionally). All the versions used to resolve the conflict are backed up before the files are removed.
This is what xx-svn-resolve does. If you give it a directory, it also finds and loops through all the conflicting files recursively to resolve them graphically.
After a long session of work in various checkouts, having to type up commands to decide what to do with each unregistered file is a bit tiresome. I wrote an interactive script to handle that.
This script runs an svn status, outputs that for you to see, and then queries the user for what to do with each file that is not registered with Subversion. You can add it, delete the file (with or without backups), mask it (setting the svn:ignore property on the parent directory), and more.
Here is an example session:
banane:$ svn-foreign Status ------ M current/todo.txt ? cv/cv.pdf ? cv/cv.aux ? cv/cv.log M cv ? reading/reviews/books/the-da-vinci-code.txt => [Add|Del|Mask|Ign|View|Quit] 14699 cv/cv.pdf ? d Backed up to: '/tmp/svn-foreign.xYz8nm/home/blais/tmp/priv/cv/cv.pdf' => [Add|Del|Mask|Ign|View|Quit] 8 cv/cv.aux ? m --(current svn:ignore on 'cv')-- ---------------------------- Add pattern (! to cancel, default: [cv.aux]):*.aux property 'svn:ignore' set on 'cv' ---------------------------- *.aux ---------------------------- => [Add|Del|Mask|Ign|View|Quit] 6265 cv/cv.log ? d Backed up to: '/tmp/svn-foreign.xYz8nm/home/blais/tmp/priv/cv/cv.log' => [Add|Del|Mask|Ign|View|Quit] 1689 reading/reviews/books/the-da-vinci-code.txt ? a A reading/reviews/books/the-da-vinci-code.txt (Done.)
svn-foreign is included with the xxdiff scripts, because it is used internally by some of the them, and also because it reuses the backup module of the xxdiff scripts. You can copy its file separately and it will still work (minus the backups).
[2008-02-15] Apparently there is a new version of the merge code that supports invoking xxdiff directly for doing merges. I have not tried it yet, but this should become the way to go once it is released and stable.
xxdiff already works pretty well with Mercurial for viewing differences, all you have to do is to add the following to your .hgrc file to view diffs graphically:
[extensions] extdiff = [extdiff] cmd.xdiff = xxdiff opts.xdiff = -r
However, graphical conflict resolution during merging requires a wrapper script that will invoke xxdiff in decision mode and that will automatically save the merge results where Mercurial expects them. The script is called xx-hg-merge, and you will need to add the following to your .hgrc:
[ui] merge = xx-hg-merge
I maintain some of my more sensitive personal data in ascii-armored encrypted files in an CVS/Subversion repository. I can open, modify and save the files from within Emacs without ever writing a non-encrypted version on disk. This means that if I edit the files in two different machines, the merge operation will surely fail, because the encrypted file does not merge. This happens rarely, but when it does, it is quite a problem: for each of the conflicting file, I must:
This is quite time-consuming. Let's automate!
This script will do all of the above for two encryped files, and it also attempts to minimize the amount of time that a decrypted file will live on disk--if needed at all. In the cases where it needs to temporarily write decrypted text to disk, as soon as xxdiff finished gulping the files in, it deletes them right away. This is not the super-dooper safest way of doing this, but it sure beats doing it all by hand [2].
It also supports unmerging CVS conflict markers in order to obtain the original and the new file automatically. For example:
xx-encrypted --unmerge my_secrets.asc
| [2] | xxdiff could be enhanced to accept input from multiple file descriptors to avoid having to use temporary files in most cases. This just has not been done yet. |
I would like to be able to apply a patch to a temporary copy of a set of files, and then to visualize the patch's changes, pick and choose the ones that we want using xxdiff, and apply them to the original files. I have started doing some work on this in the xx-patch program, but there remains some unsolved issues:
For these reasons, until I find a good solution for all of these problems, the xx-patch code remains hidden in the codebase. If you're interested in working on this let me know.
One annoying problem is that of migrating a database from one schema to another. A typical web application setup has the stable codebase running on the server, and test setup running the some other machine, on which the programmer makes changes and develops new features.
In the course of doing so, a database-based application involves changing the database schema, that is, adding columns, changing types, tables, indexes, and the like. In an ideal world, a developer would be careful to take note of all the required changes. Oh, by the way, we're not living in an ideal world.
One problem is that when upgrading the code of the application on the production machine, the existing database has to be migrated to fit the new schema that corresponds to the new code. This is usually carried out “by hand” on the database's shell interface, or by writing a script (if you're a Python hacker), and can be quite tricky, it is very easy to forget some things and to make mistakes.
Since we're in the business of comparing things, I wrote a script that fetches the schemas of two databases, parses the schema description, outputs two files with appropriate garbage so that corresponding objects line up when diffed, and I run xxdiff on them. This results in a nice side-by-side view of the differences between the objects of the two schemas, and allows you to clearly view what needs to be carried out for the database migration task.
Currently, only the PostgreSQL database is supported, but it would be quasi-trivial to add support for other databases.
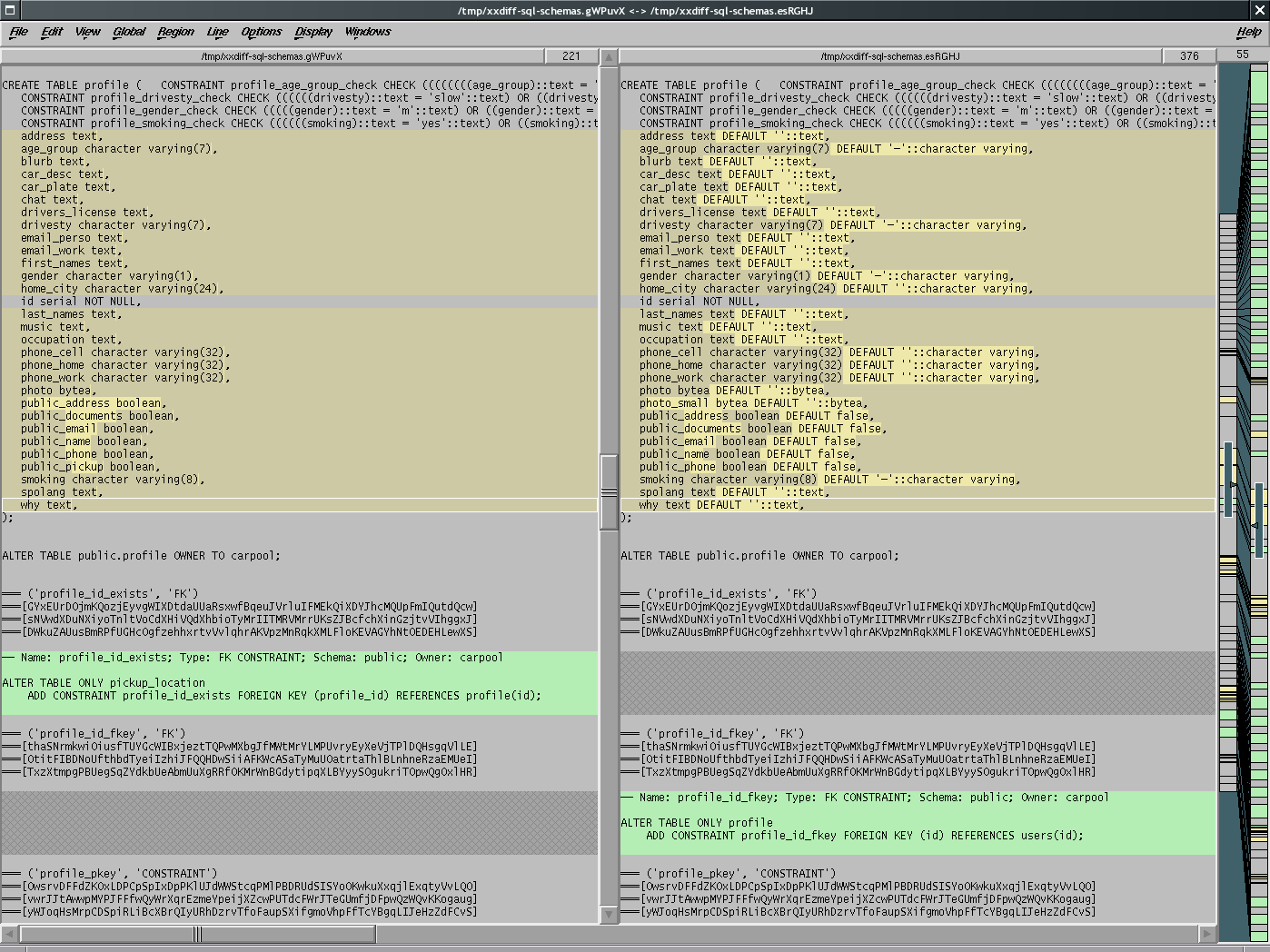
SQL Schema comparison.
xxdiff can be used to compare pairs of corresponding objects, and I'm sure that there are many other exciting uses that people can apply it to.
Use the provided scripts as examples. There are many convenient functions in the package that you can leverage from to write your own processing scripts around xxdiff.
Any questions should be directed to Martin Blais <blais@furius.ca>. Contributions appreciated. If you find these programs useful, drop me a note.