| Author: | Martin Blais <blais@furius.ca> |
|---|
Contents
This is the documentation for Snakefood, a dependency graph generator for Python source code (written in Python).
In this document, dependencies are import relationships between Python source files. If file a.py imports some code from file b.py, we say that a.py depends on b.py, or that a.py has a dependency on b.py.
Controlling the dependencies between the various parts of your code (or between projects that your code uses) is a powerful way to increase the reusability of your code: the least amount of dependencies a body of source code has, the greater the likelihood that this code will be usable in the future. Dependencies cause codes to break due to the independent evolution of modules and changes in the interfaces. Even within a single project, controlling dependencies between layers is the essence of modularity.
Snakefood allows you to automatically generate a visual graph of those dependencies. When you produce these kinds of graphs, you will often be surprised at how certain parts of your code inadvertently become tied together. Dependency graphs allow you to view the relationships clearly and will generate questions about the high-level organization of your code and allow to improve modularity and reusability.
(For the impatient.) You will need Graphviz. Snakefood generates a dot file (Graphviz input file). Here is the simplest way to generate a graph [1]:
sfood /myproject | sfood-graph | dot -Tps | pstopdf -i | xargf acroread
However this will probably not do what you want, unless your project is pretty small. The dependency graphs for reasonably sized projects are generally complex, and you will want to filter out some of the dependencies, and cluster some of them in logical groups of files or by directory (see the text for the sfood-cluster tool).
Read on for more details on how to use these tools.
| [1] | See http://furius.ca/pubcode/ for the xargf tool. |
You need to install Python-2.5 or greater.
You need to Graphviz tools to generate graphs. Snakefood produces input files for Graphviz.
To install the Snakefood tools themselves, just run the usual distutils command:
cd snakefood-<version> python setup.py install # as root
Snakefood provides a few main tools:
Typically, you will use sfood to generate the dependencies and pass those on to sfood-graph, then pass its output to dot to generate your output PDF file.
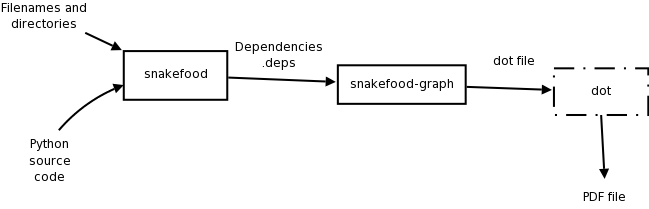
Simple pipeline for generating a full dependency graph.
For details on using the tools, call each program with the --help option.
To generate the dependencies, you use the sfood tool, giving it a list of filenames:
sfood file1.py file2.py file3.py
You can also use directories:
sfood /path/to/my/project
If you specify directories, sfood will recurse through them and automatically find all the Python source files and process them. Each file is processed independently, giving the file to sfood means “output the dependencies of this file”.
sfood finds the dependencies in your source files using the AST parser. It does not figure out which import statements run conditionally; it simply finds all the imports in the file and outputs dependencies for each of them.
Note
Note that none of the module your specify on the command-line are loaded nor run. Loading modules is almost always problem, because a lot of codebases run initialization code in the global namespace, which often requires additional setup. Snakefood is guaranteed not to have this problem: it does not run your code, it just looks at it; the worst thing that can happen is that it misses some dependencies.
A problem with dependency trackers that run code is that they are unreliable too, due to the dynamic nature of Python: the presence of imports within function calls and __import__ hooks makes it almost impossible to always do the right thing. This script aims at being right 95% of the time, and we think that given the trade-offs, 95% is good enough for 95% of its uses.
For each file or directory that you specify on the command-line, sfood automatically figures out which root it lives in. What we call a “root” in this document is a directory that should be in PYTHONPATH if you were to import the given files from a script.
Snakefood finds the package roots,
All of the package roots found this way are automatically prepended to the Python import path, so you do not have to configure your PYTHONPATH before you invoke sfood. sys.path is in effect when processing imports. It is simply augmented to include the roots that snakefood found
The roots are added to the module path and used to separate the filename in two parts: the package root, and the filename relative to that root (see the section on dependencies format below).
By default, sfood does not follow dependencies, that is, if you ask it to process a.py and it finds that it has a dependency on b.py, the file b.py does not get processed for its dependencies.
Use the --follow option to tell sfood to follow its dependencies. Files for each target dependency that were found are automatically examined for dependencies, and the process continues until all leaves are found (we check for cycles too).
Normally you will want to find out the relationships only between files in the packages that you provide on the command-line. For example, you will probably not be interested to find out about dependencies to the modules in the standard library that comes with Python.
You can filter out the dependencies by yourself using the usual UNIX tools, like grep or sed. But since this is a typical case, there is a convenient --internal option to sfood that automatically limits dependencies to only those files living in the package roots corresponding to the set files that you specify on the command-line.
You can restrict the dependencies even further, to only the list of files that have been processed, that is, the list you specified on the command-line in the first place. You enable this by using the --internal option twice. This is a convenient feature when you want to chart the dependencies of only the files in a subdirectory of a larger project.
Note
Subdirectories that live under a package root but which do not have an appropriate __init__.py file are considered external to the containing package root (because they are distinct). Large codebases often have such directories containing test scripts, installation code and what not, which cannot be imported directly. Add those directories to the command-line if you want to include them while using the --internal option, or generate raw dependencies and filter with grep.
With the --ignore-unused option, sfood will automatically ignore dependencies motiviated by symbols imported but not used. This determination is performed using the same conservative and safe heuristic as is used in sfood-checker.
The resulting list of dependencies will always be smaller when running with this option than without. Note that the resulting dependency tree is the same that you would obtain should you clean up all the analyzed code using sfood-checker, to hunt for unused imports.
The format of dependencies is really simple:
((<source_package_root>, <source_file.py>), (<dest_package_root>, <dest_file.py>))
where the package_root files are the directory names at the root where the module files are found, and the file.py names are the Python filenames relative to the corresponding root.
Each line is a valid Python tuple expression, so you can easily write a Python script to process them using a line like:
for dep in map(eval, sys.stdin):
...
and output them like:
dep = (froot, fn), (troot, tn) print repr(dep)
The process of building a nicely filtered dependency graph is iterative, you will typically massage the dependencies to highlight the relationships that you care about. Since calculating the dependencies can be a slow process (and filtering and graph generation is not), we recommend to save the output of sfood to a file and work from that.
You may see a lot of warnings when you run sfood. This is normal. There are a few reasons for this:
The code you are analyzing requires some external packages that are not installed or not in your PYTHONPATH;
The from-import Python syntax is ambiguous; for example, in the following code, it is not clear whether table is a module or an object defined in the database module:
from database import table
Therefore, sfood does not normally print out warnings for these. If you want to see a list of those failed imports, run it with the --verbose option.
In eitehr case sfood keeps running and produces all the other dependencies that it finds.
To insure that all the file nodes show up in the graph, for each processed file we output a line like this:
((<source_package_root>, <source_file.py>), (None, None))
The graphing tool interprets that to mean it has to at least create a node for <source_file>.py, even if it has no dependency. Scripts you write to filter the dependencies need to be able to interpret those lines appropriately.
Sometimes when an import statement is wrapped in a conditional, you may want to avoid generating a dependency for that statement, for example:
try:
import superhero
except ImportError:
# superhero not available. We fallback on evilgenius.
import evilgenius
In this example, you may want to avoid having snakefood follow dependencies to superhero, because your software can run fine without it (that is, with evilgenius). To that effect, snakefood looks for a string after the import statement, and uses that string as a hint to modify its actions, for example, this will tell sfood to not output the dependency for superhero:
try:
import superhero; 'OPTIONAL'
...
This is especially useful with the --follow option, when you want to avoid dragging a large dependency in the dependency list.
Since dependencies are simple line-based Python expressions, you can use grep or sed to filter out or modify unwanted lines:
cat raw.deps | grep -v /usr/lib/python | sfood-graph > out.dot
There is no formula for filtering or reformatting the dependencies; it depends on your codebase and what you want the graph to show.
A useful operation is to transform the relative filenames into logical groups and to remove redundant lines. We call this “clustering”. A common example is to lump together all the filenames that start with a particular directory prefix.
You could do this with sed but you also need to remove redundant lines to do it properly, i.e. after simplification of the relative filenames, multiple lines will be equivalent. sfood-cluster does that automatically. You create a file of cluster names:
pack1 pack2
and a dependency file will be transformed from this:
(('/myproject', 'pack1/person.py'), ('/myproject', 'pack1/employee.py'))
(('/myproject', 'pack1/person.py'), ('/myproject', 'pack1/manager.py'))
(('/myproject', 'pack1/person.py'), ('/myproject', 'pack2/boss.py'))
to this:
(('/myproject', 'pack1'), ('/myproject', 'pack1'))
(('/myproject', 'pack1'), ('/myproject', 'pack2'))
Here is how to use the sfood-cluster tool:
sfood /myproject | sfood-cluster -f clusters | sfood-graph > myproject.dot
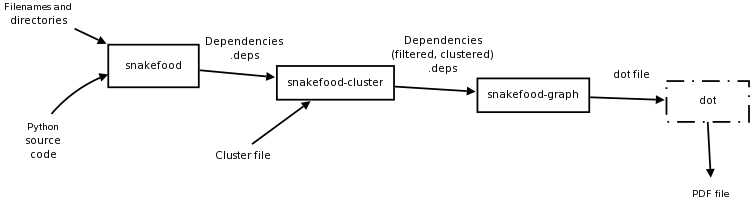
Pipeline for dependency graph with clustering.
You can either create the clusters file manually, or with a find or ls command in your source tree."
If you will repeatedly compute the dependencies for a codebase that you maintain, you could write a simple script to do all the custom things that you need to, for example:
# Generate the raw dependencies. sfood /myproject > /tmp/raw.deps # Filter and cluster. cd /myproject ; ls -1d * > /tmp/clusters cat /tmp/raw.deps | grep -v test_widget | sfood-cluster -f /tmp/clusters > /tmp/filt.deps # Generate the graph. cat /tmp/filt.deps | sfood-graph -p | dot -Tps | pstopdf -i -o /tmp/myproject.pdf
While this will work, a better way to write such a script is to use a makefile.
Here is an example for a simple self-contained Makefile that will process the relevant dependencies as above:
NAME = myproject
ROOT = /path/to/myproject
PDFS = $(NAME).pdf
.SUFFIXES: .deps .dot .pdf .clusters
all: $(PDFS)
raw.deps: $(ROOT)
sfood -i $(ROOT) $(FOOD_FLAGS) > $@
$(NAME).clusters: $(ROOT)
cd $(ROOT) ; ls -1d * > $(shell pwd)/$@
$(NAME).deps: $(NAME).clusters raw.deps
cat raw.deps | sfood-cluster -f $< > $@
.deps.pdf:
cat $< | sfood-graph | dot -Tps | ps2pdf - $@
clean:
rm -f *.clusters *.dot *.pdf
ls -1 *.deps | grep -v ^raw.deps | xargs rm -f
realclean: clean
rm -f raw.deps
For a set of more reusable make rules, take a look at snakefood/test/Makefile.rules and the Makefiles that we use to run out tests on existing codebases. You can probably leverage this for your project (feel free to copy and modify it as needed).
If you only want to list the imported symbols and modules, without having the tool try to find the file where the modules are to be found, you can use the complementary tool sfood-imports, which essentially replaces grepping the files for imports.
sfood-imports also disambiguates local imports from globals by looking for files below the level of the file that is imported, in the same way that sfood does.
For example, to list the imports from sfood, I do this:
sivananda:~/p/snakefood/bin$ sfood-imports sfood sfood:20: sys sfood:20: os sfood:20: logging sfood:20: traceback sfood:20: re sfood:21: imp sfood:21: compiler sfood:22: os.path sfood:23: collections.defaultdict sfood:24: operator.itemgetter sfood:25: dircache.listdir sfood:151: imp.ImpImporter sfood:153: pkgutil.ImpImporter sfood:324: optparse
Also, see the --unified option which will output a single set of unique imports for a set of files.
Another tool that comes with Snakefood is a program that checks for unused and redundant imports. Just run it on files or directories (it recurses and finds the Python source files). For example:
~/p/.../python/xxdiff$ sfood-checker invoke.py /home/blais/p/xxdiff/lib/python/xxdiff/invoke.py:290: Redundant import 'optparse' /home/blais/p/xxdiff/lib/python/xxdiff/invoke.py:11: Unused symbol 'os'
There are other lint-like tools to do import checking out there; a problem with most of these tools is that they attempt to import the modules they analyze, which often fails because of code with side-effects that runs at global module level. sfood-checker does not import the code it analyzes, rather, it uses the AST to perform a "good-enough" analysis. The reason for building this import checker is the same as the reason for making snakefood: it always works on your code, no matter what; it provides a "good enough" / 99% accurate solution that at least, always "just works".
If you are importing a file for its side-effects only, sfood-checker has no way to detect this and will report the import as unused. To avoid this, use a pragma after the import statement to disable the warning:
# Importing for side-effects only. import injectrace; 'SIDE-EFFECTS'
This section documents original ways in which you can use this program.
If a codebase has some package dependency relationships that should be enforced, for example, that anything in package root.core should not depend on anything in package root.util, you can easily write a post-commit hook in your favorite source code versioning system that will run sfood on an up-to-date checkout and grep for the offending relationships. Such a script could send an email to the checkins list, or even refuse to commit if the offending dependency occurs.
It is often required to extract a portion of a codebase outside a source tree, in a way that the extracted software will still be functional. In other words, you sometimes have to extract a script and all the dependencies that it drags along with it to remain usable.
You can easily use snakefood for this purpose: run sfood --follow --internal on the given script, and it should produce the list of dependencies that it needs to continue functioning. Flatten these dependencies into a list of filenames with sfood-flatten and copy the files somewhere else.
I wrote this script in may 2007. I had previously tried to write a reliable dependency grapher about 4 or 5 times, giving up each time on the various intricacies of the Python import semantics. I'm pretty happy this time that I've found something reasonably reliable that works everywhere, and I'm fully committed to fixing any bugs you may find and to bring this project to a stable version 1.0 state, where it can be used ubiquitously on all Python projects. Comments, feedback and donations are welcome. I hope you find this program useful.